


Continuing the series of NLP, as told in my previous post, I will discuss about Foundational Language Models. Language modeling (LM) uses statistical and probabilistic techniques to determine the probability of a given sequence of words occurring in a sentence. Hence, a LM is basically a probability distribution over sequences of words:
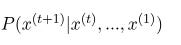
Here, the expression computes the conditional probability distribution where can be any word in the vocabulary.
LMs generate probabilities by learning from one or more text corpus. A text corpus is a language resource consisting of a large and structured set of texts in one or more languages.
One of the earliest approaches for building a LM is based on the n-gram. An n-gram is a contiguous sequence of n items from a given text sample. Here, the model assumes that the probability of the next word in a sequence depends only on a fixed-size window of previous words:
P (“There was heavy rain”) = P (“There”, “was”, “heavy”, “rain”) = P (“There”) P (“was” |“There”) P (“heavy”| “There was”) P (“rain” |“There was heavy”)
As it is not practical to calculate the conditional probability, but this is approximated to the bi-gram model as:
P (“There was heavy rain”) ~ P (“There”) P (“was”|”There”) P (“heavy” |”was”) P (“rain” |”heavy”)An N-gram model is a type of probabilistic LM that predicts the next item in a sequence based on the previous n-1 items. For example, if n=2, the model is called a bigram model and it predicts the next word based on the previous word. If n=3, the model is called a trigram model and it predicts the next word based on the previous two words.
Keep reading with a 7-day free trial
Subscribe to STJayaprakash's AI-Aqua Substack to keep reading this post and get 7 days of free access to the full post archives.